우선, 본인은 한이음 프로젝트를 통해 헬스 동작을 분석 하는 서비스 를 만들고자 딥러닝 기술을 사용하기로 했다.
처음으로 접하기 때문에, 딥러닝 모델이 어떻게 작동하는지, 어떤 신경망을 사용하는지, 어떻게 학습시키는지, 어떤 모델을 어느 상황에 써야하는지 등등 여러가지를 공부했어야 했다.
우선, CNN에 대해서 이 글에서 설명을 하고 다른 모델을 왜 사용하지 않았고 그것들만의 특징들에 대해서 적도록 하겠다.
CNN 모델
CNN이란?
데이터로부터 직접 학습하는 딥러닝의 신경망 아키텍처
CNN의 특징
- 영상에서 객체, 클래스, 범주 인식을 위한 패턴을 찾을 때 자주 쓰인다.
- 수십개 수백개의 계층을 가질 수 있고, 각 계층에서 영상의 서로 다른 특징을 검출한다.
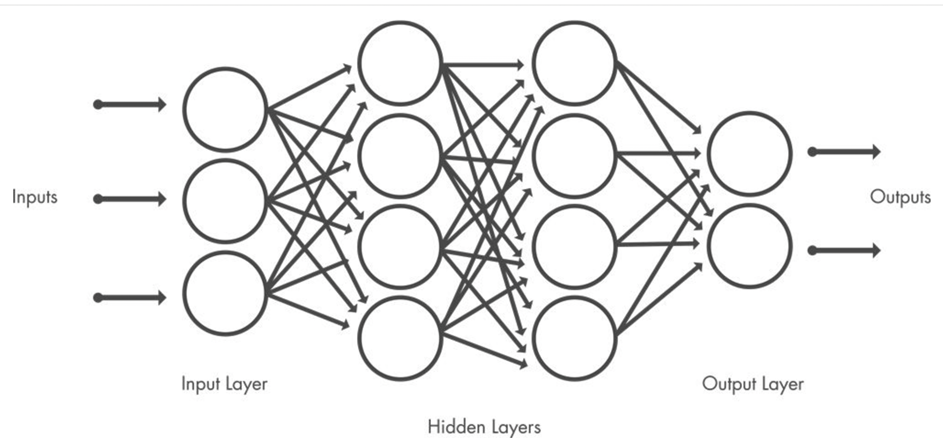
- Input Layer, Hidden Layers, Output Layer 로 구성된다.
- 가장 일반적인 3가지 계층으로 컨볼루션 계층, 활성화 계층, 풀링 계층이 있다.
왜 CNN을 선택했는가?
→ CNN 모델은 동영상에서 객체에 대한 인식을 하는데 사용되며, 사용자에게 운동 영상을 업로드받아 딥러닝 모델의 입력값으로 넣어줘야하는 본 프로젝트에서는 RNN 모델보다 CNN 모델이 적합하다고 판단
본인의 프로젝트에서 CNN을 어떻게 정의했고 컴파일했으며, 학습시켰는지에 대해 설명하겠다.
CNN 모델 정의
- Conv2D Layer 를 추가하여 2D 합성곱을 수행하고, 32개의 필터, 3x3 커널 크기, 활성화 함수는 ReLU를 사용
- MaxPooling2D 레이어를 추가하여 맥스 풀링을 수행. (2x2 풀링 크기를 사용)
- 위 과정을 다시 반복하여 64개의 필터와 128개의 필터에 대해서도 2D 합성곱과 맥스 풀링을 수행
- Flatten 레이어를 추가하여 3D 텐서를 1D 벡터로 변환
- Dense 레이어를 추가하여 128개의 유닛과 ReLU 활성화 함수를 사용
- 마지막으로 Dense 레이어를 추가하여 1개의 유닛과 sigmoid 활성화 함수를 사용하여 이진 분류를 수행
이러한 과정을 통해 CNN 모델을 정의하였다.
위에서 CNN의 특징에 대해서 말했듯이 많은 계층을 가질 수 있으며 각 계층에서 다른 특징을 검출한다.
모델 컴파일
→ ‘adam’ 옵티마이저를 사용하여 모델을 컴파일하고, 손실함수로 ‘binary_crossentropy’ 를 사용
컴파일을 하기 위해서는 옵티마이저를 정하고, 손실함수를 결정해야 한다.
(많은 유저가 adam 옵티마이저를 많이 사용한다.)
모델 학습
- 입력 데이터 X_train 해당 데이터 레이블 y_train 데이터를 사용하여 모델을 학습
- epoch 횟수와 배치 크기를 알맞게 설정
- 학습 데이터의 20%를 검증 데이터로 사용

학습을 진행 시키면 위의 예시와 같이 epoch 횟수만큼 돌리다가 학습을 종료한다.
그리고 Loss(손실)과 정확도를 유저에게 보여준다. ( print를 통해서 확인해야 함 )

cnn 모델을 학습시키는 데에 사용된 코드들이다.
이 과정 뿐만 아니라, CNN에게 입력값을 넣어줄 영상을 processing해주는 메서드도 필요하다.
이는 개발자가 어떻게 할지에 따라 변경해서 사용하면 된다.